Faster (sometimes) Associative Arrays with Node.js
Friday, May 13, 2011I had been meaning to spend some time with Judy Arrays but I hadn't quite found a good reason to explore them to their full extent. While attending NodeConf I caught Marco Rogers' talk on C++ bindings for Node.js which gave me a fantastic reason to spend some time in the Judy world. A few days later I came up with this project: Judy Arrays in Node.js. Unfortunately, it's been about half of a decade since my last foray into C++, and at least a decade and a half before that via academia, so while all attempts have been made to adhere to best standards of Node.js add-on development, I cannot guarantee that everything is 100% correct and that there are no memory leaks.
One of the weaknesses of Node.js is the speed and memory usage of native associative arrays. They are slow, require a lot of garbage collection, and don't do well with repeated access. Judy arrays attempt to fix by providing very fast and low memory access to associative arrays. This implementation manages to avoid the native garbage collection (moving it all back to the operating system), as well as implement faster access to values than native access provides.
Moving anything into C++ from Node.js adds a lot of overhead. This overhead is much less obvious at high iterations, which means that in reality the gains with Judy Arrays are really only obvious in long-running applications with a lot of array accesses. Instantiation of a Judy Array via Node.js is very slow. While you can control the overall size of the array being generated, in reality there is still mapping happening from an interpreted language to a compiled language. This is not fast under the best of terms, let alone via the naive malloc() and free() calls that I chose to implement this in this context. A quick note though: these benchmarks are pretty contrived; I took pains to try to replicate real-world performance, but this may not be equivalent to what you will see in application.
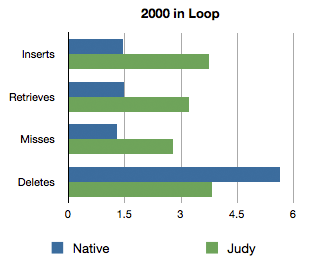
At 2000 iterations, instantiation overhead is less noticeable, allowing Judy Arrays to excel due to quick sequential and random access to data. Since the Judy Array manages its own memory with this implementation, delete() calls are much slower.
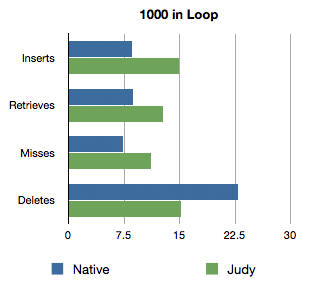
At 1000 iterations, native implementation starts to catch up. This is due to the time needed for each instantiation of the Judy Array.
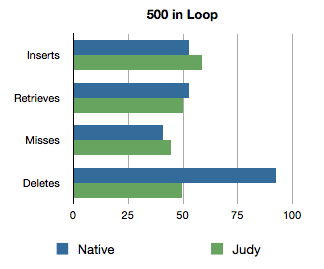
At 500 iterations, equality happens. This shows the weakness of converting interpreted JavaScript code to C++ in v8, a whole lot of overhead with memory allocation and conversion.
Giant warning: my C++ is pretty rusty at this point. While I spent some time doing cleanup of the Judy implementation that I chose, none of the code is guaranteed to be pretty. This is your opportunity to fork and improve it.
Node-Judy on GitHub